.jpg?width=2097&height=770&name=ALP%20logo%20%26%20strapline%20-%20RGB%20(US%20version).jpg "Artificial Lift Performance - Optimizing Oil Production")
Do you want your ESPs to be the Tom Brady of quarterbacks? Whether you’re a fan or not, Tom’s track record is impressive, especially his most recent Superbowl win. To be so successful has required intelligence, hours of (proper)practice, the right mindset, change and dedication to being a superstar. He has done things differently from other quarterbacks. Success with ESPs is the same and requires things to be done differently.
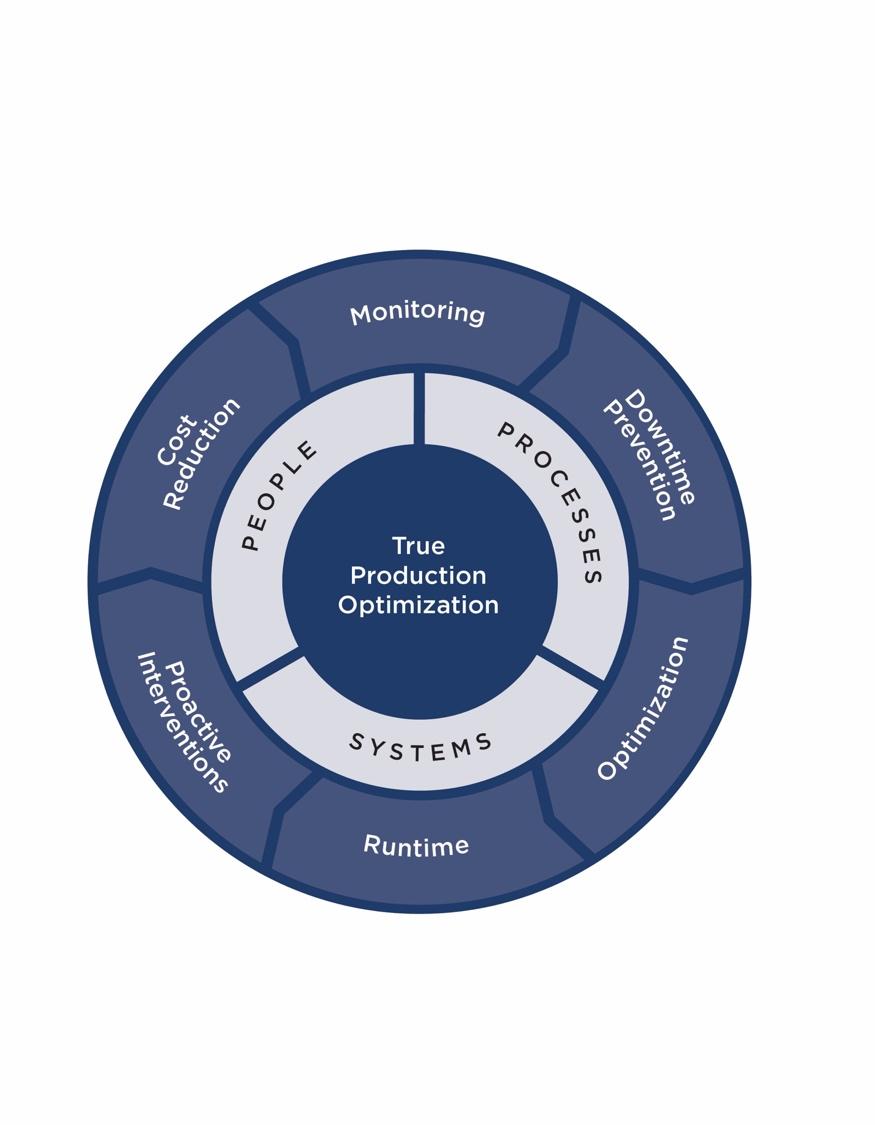
Getting ESPs (or any artificial lift method) to produce at lower cost/bbl requires trained staff, appropriate systems, good processes and attention to detail.
In a previous blog we identified some best practices related to gaslift, we thought we’d do the same for ESPs. Our best practices are based on our “True Production Optimization” process. If you’d like to know our top twenty best practices to solve your ESP problems….read on …..
ESP Best Practices
Reduce Downtime
Keep your ESPs running all the time - that puts oil in your tanks and ultimately money in your bank account. When ESPs have downtime, track the associated downtime, code it and calculate the associated lost production. Monthly, review the causes of downtime ranked by production loss and identify if there are specific actions you can take to reduce downtime. In this day and age having a pumper manually enter such information into a database at the end of the day is highly inefficient. Downtime capture can be completely automated.
- Automate downtime capture
- Calculate lost production for each downtime event
- Code downtime into discernible buckets (around 20 categories)
- Review monthly statistics for lost production due to downtime, identify preventable downtime and take action to eliminate or reduce it.
Minimize Offline Production Time
Offline production due to a well being non-producible, is normally due to a failed ESP but could be for facility issues, power plant problems or fluid handling constraints. Again, track and code such downtime and work to minimize offline time.
For the ESP (or any lift method), the replacement system can be known, prior to the ESP failing, the tools exist to automate this process. That way, you can have discussions with your vendors monthly and ensure replacement equipment will be available (and of the correct specification – more on this later) so that the time from ‘discovery to recovery’ is kept at a minimum, allowing you to quickly put production back in your tanks.
- Know the IPR of your wells
- Proactively know what the replacement ESP should be before it fails.
- Share that information with your vendor. Review on a monthly basis.
Surveillance and Production Optimization
We install ESPs to produce oil. Ensuring they are functioning optimally means being able to do two things: identify when you are losing production because of an ESP problem (that has often existed since installation); identify opportunities to gain a known amount of production from the existing ESP. Again, this determination can be completely automated so that the ESP performance is known for every production test and optimization opportunities identified. This approach when combined with management by exception processes allows the Production Engineer to use his time effectively to manage his wells.
- Rank your wells by oil production rate. Start the optimization process with higher rate wells. 10% additional production on a good well is worth more than 10% of a dog well.
- Use alarms to catch changes in operating conditions. Automate the surveillance process – machines catch exceptions quicker than people and work 24 hours/day.
- Analyze every test automatically to ensure that ESP performance is known, well production is optimal and that the IPR is known.
Proactive Interventions
If you can identify that an ESP has a problem (wear, broken shaft, etc. that reduce the pump TDH) resulting in reduced production, or the ESP is undersized for the potential of the well, it can be desirable to change out the ESP and gain additional production. This is obviously an economic evaluation. The ability to recognize and evaluate such opportunities automatically should be part of your ESP surveillance process.
- Use automated diagnosis to flag ESP issues that result in lost production
- Use automated diagnosis to identify wells that are candidates for ESP upsizing
Extending Runlife
Many clients tell us they would like their engineers to be better at design, but I think that’s a red herring. Design tells you the pump flowrate range, number of stages, motor HP and VSD size. But, beyond that there is so much more…the specification of the system. It’s a bit like saying give me a 3000 sq ft house on a golf course with 5 bedrooms. That could be ideal if you define each room specifically. Otherwise, your partner is likely to give you hell if you end up with no en-suite in the primary bedroom. ESPs are the same. Vendor selection, partnering, stocking agreements and specification definition are critical (and should be based on metrics other than lowest cost) – all of this requires a planned approach to what goes in your well.
In a recent blog article published by Extract, a statistic was:
“US companies leasing 70% or more of their ESPs listed average runtimes for those pumps before failure at 16.44 months. The median number was 12 months. Companies who purchase at least 70% of the time reported average runtimes before failure at 25.80 months, with a median of 24.00—twice as long as for leased pumps”
Read the whole blog here. My own personal preference is a pay for performance model where the vendor is compensated based on how long the ESP runs. Zero hours is the shortest runlife for an ESP, two years is a typical longevity and 19.7 years is the oldest ESP that I know of. In challenging conditions, 90-day runlives can be typical if the system is inappropriate for the conditions. I’d pay more for a system that runs two years…..but I’d do that prorated on a performance basis. Rafael Lastra in his excellent paper on The Quest for The Ultrareliable ESP stated:
“Current business models for sourcing ESPs are faulty, commoditization is the biggest deterrent for reliability improvement. ESP equipment cost is usually a small fraction of the operational cost and many operators do not realize that the bigger prize is in improving reliability and availability, not in acquiring inexpensive equipment.”
I agree. Improve the specification, pay a bit more and improve your reliability / runlife.
Improving ESP reliability needs to focus on tearing down all systems, understanding the failed component, failed subcomponent and root cause of the failure. Ensuring the future system(s) are specified to address these issues through equipment specification are key. Tracking lagging failures is also really useful to give insights into other aspects of the specification that need to be improved. And, don’t forget to pay attention to the power quality of the electricity going to your ESP.
Lastly, even once you have the correct specification the equipment needs to be assembled, installed, commissioned and operated correctly. This requires engineers and technicians that have a vested interest in your ESPs running a long time. One of our clients has seen significant runlife improvement through having their own ESP technicians.
- Perform two-point designs to cover current conditions and 18-24 months ahead
- Implement a downhole ESP power quality specification (download the paper)
- Coat pump stages and use enhanced stabilization to facilitate low rates later in the pump life (sand / proppant production)
- For more than ~30 wells hire your own technician(s) to QA the installation process and perform regular troubleshooting.
- Teardown all systems and identify root cause of failure and corrective action to prevent recurrence.
- Use pumps that have downthrust protection and a low minimum rate.
- Partner with one or two vendors and evolve the specification for your wells that the vendor will keep in stock
- Implement a pay for performance contracting model
